- 컬렉션: 여러 객체를 모아 놓은 것을 의미
- 프레임웍: 표준화, 정형화된 체계적인 프로그래밍 방식
- 컬렉션 프레임웍
컬렉션(다수의 객체)을 다루기 위한 표준화된 프로그래밍 방식
컬렉션을 쉽고 편리하게 다룰 수 있는 다양한 클래스를 제공
컬렉션 프레임웍의 핵심 인터페이스
- List: 순서가 있는 데이터 집합 데이터 중복허용 (대기자 명단)
- Set: 순서를 유지하지 않는 데이터의 집합. 데이터의 중복을 허용하지 않음(네발동물집합)
- Map: 키와 값의 쌍으로 이루어진 데이터의 집합. 순서 없음/ 키중복 안됨/ 값중복가능(아이디비밀번호)
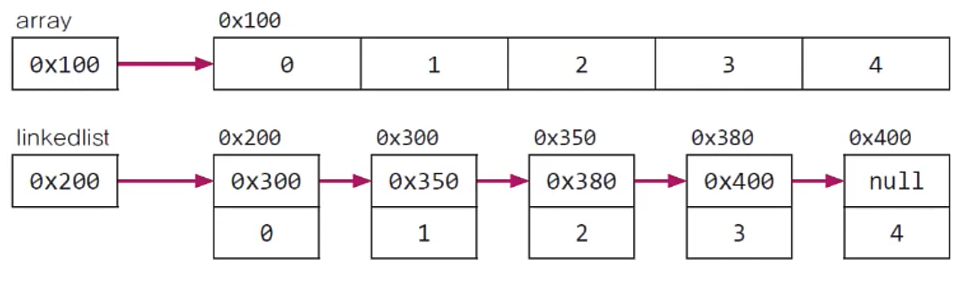
- List: 벡터, 어레이리스트*, 링크드리스트*
- ArrayList: 기존의 벡터를 개선한것 벡터는 동기화 됨 순서유지 중복허용
데이터의 저장공간으로 배열(array) 사용
- 링크드리스트
배열장점: 배열은 구조가 간단하고 데이터를 읽는 데 걸리는 시간이 짧다.
배열단점: 크기를 변경할 수 없다. 크기를 변경해야 하는 경우 새로운 배열 생성 후 데이터 복사, 큰배열 메모리 낭비
비순차적인 데이터 추가삭제 시간 많이 걸림/순차적인건 빠름
->링크드 리스트는 배열의 단점을 보완
배열과 달리 링크드 리스트는 불연속적으로 존재하는 데이터를 연결 (노드)
데이터의 삭제: 단 한 번의 참조변경만으로 가능
데이터의 추가: 한번의 노드객체생성과 두번의 참조변경으로 가능
class Node{
Node next; 다음 노드
Object obj; 데이터
}
단점: 불연속적 데이터 접근성 나쁨
-> 더블리 링크드리스트: 이중연결리스트 접근성 향상 양쪽으로
class Node{
Node next; 다음 노드
Node previous; 이전 노드
Object obj; 데이터
}
인덱스가 n인 데이터의 주소= 배열의 주소+n*데이터 타입의 크기
- List: 해쉬셋, 트리셋
- Map: (링크드)해쉬맵, 트리맵
- 스택: lifo(last in first out)구조. 마지막에 저장된 것을 제일 먼저 꺼냄(밑 막힌 상자) 저장push 추출pop 배열효율
활용: 수식계산, 수식괄호검사, undo/redo, 웹브라우저 뒤로/앞으로
- 큐: fifo(first in first out) 구조 제일 먼저 저장한 것을 제일 먼저 꺼냄(줄서기) 저장offer 추출poll 링크드리스트
인터페이스 객체생성 안됨, 큐 구현한 클래스 사용(링크드리스트)
활용: 최근사용문서, 인쇄작업 대기목록, 버퍼(줄서기)
- Iterator, ListIterator, Enumeration: 컬렉션에 저장된 데이터를 접근하는데 사용되는 인터페이스
컬렉션에 저장된 요소들을 읽어오는 방법을 표준화한 것
- Map에는 iterator()가 없다
- Arrays: 배열을 다루기 편리한 메서드 제공
배열출력 toString()
배열복사 copyOf(), copyOfRange()
배열 채우기 fill(),setAll()
배열 정렬과 검색 sort(),binarySearch()
다차원배열 출력 deepToString()
객체정렬에 필요한 메서드(정렬기준) 제공 인터페이스
- Comparable:기본정렬기준 compareTo()
- Comparator: 기본정렬기준 외 다른기준 compare()
- 두객체 비교결과 반환 같으면0/ 오른쪽 크면 음수/작으면양수
- 해쉬셋: 순서 없음 중복안됨
set인터페이스를 구현한 대표적인 컬렉션 클래스
순서 유지하려면 링크드해쉬셋 클래스 사용
객체를 저장하기전에 기존에 같은 객체가 있는지 확인, 없으면 저장
- 트리셋: 범위검색과 정렬에 유리한 컬렉션 클래스
해쉬셋보다 데이터 추가삭제 시간 더걸림
이진탐색트리로 구현 범위탐색과 정렬에 유리
이진 트리는 모든 노드가 최대 2개의 하위노드를 갖음
class TreeNode{
TreeNode left;
Object element;
TreeNode right;
}
이진탐색트리: 부모보다 작은 값은 왼쪽 큰 값은 오른쪽에 저장
단점: 데이터가 많아질수록 추가삭제에 시간이 더 걸림(비교 횟수 증가)
트리순회: 이진 트리의 모든 노드를 한번씩 읽는것 전위 중위 후위 순회
중위순회하면 오름차순
- 해쉬맵(동기화안됨), 해쉬테이블(동기화ㅇ):
map인터페이스를 구현 데이터를 키와 값의 쌍으로 저장
순서 없고 키중복안됨 값 중복가능
순서를 유지하려면, 링크드해쉬맵 클래스 사용
해싱기반으로 데이터 저장 데이터가 많아도 검색 빠름
키,value: 엔트리
- 해싱: 환자정보 관리, 해시함수 이용 해시테이블에 데이터 저장&저장위치 읽어오기
해시테이블은 배열과 링크드리스트가 조합된 형태
해시테이블에 저장된 데이터 가져오는 과정
- 키로 해시함수를 호출해서 해시코드 얻음(배열의 인덱스)
- 해시코드에 대응하는 링크드리스트를 배열에서 찾는다
- 링크드 리스트에서 키와 일치하는데이터 찾음

- 트리맵
범위 검색과 정렬에 유리
해쉬맵보다 데이터 추가, 삭제에 시간이 더걸림
- Collections: 컬렉션을 위한 메서드 제공
- 컬렉션의 동기화: synchronizedXXX()
- 싱글톤 컬랙션 singletonXX()객체 한개만
- 한 종류의 객체만 저장 checkedXXX()

'JAVA' 카테고리의 다른 글
| 쓰레드 (0) | 2022.03.10 |
|---|---|
| 지네릭스, 열거형, 애너테이션 (0) | 2022.03.09 |
| 날짜와 시간 & 형식화 (0) | 2022.03.08 |
| java.lang패키지와 유용한 클래스 (0) | 2022.03.08 |
| 예외처리 (0) | 2022.03.07 |